java8 是 java 的一个长期支持版本,也是当前开发者使用最多的一个版本,了解它,有助于代码质量,并向未来的 java11
和 java17 进军。
摘录
这里是对《Java 8 实战》的一个摘录。
Java 8 与之前的版本有什么区别?
java8 添加了一些新特性,比如 Stream API、Lambda、接口的默认方法、Optional、CompletableFuture、新的日期和时间 API
等等,其中最主要的是 Stream API 特性,基于它而引入了一种全新的编程思想——函数式编程。
从 java1.0 时代开始,大家使用线程和锁,甚至是内存模型来进行并发编程,这需要掌握一定的专业知识,包括底层的相关逻辑。
为了降低并发编程的难度,高效地利用系统的多内核,java5 添加了线程池和并发集合,java7
添加了分支/合并(fork/join)框架,它们都让并行计算变得更强大,但使用起来还是很费劲。所以 java8 提供了新的 API——Stream
流,它将数据当作一个流,然后可以对中间操作进行预定义,通过终端操作获得预期的结果。
Stream 流实例可以由集合相关接口得到,也可以通过 Stream 流的工厂方法得到,在终端操作未被调用之前,预定义的任何中间操作都不会产生作用。
Stream 流在默认情况下属于串行处理,必须显式的声明为并行流,才可以获得强大的并行计算能力。
并行流使用 CompletableFuture 维护的通用线程池进行并行计算,如果不具备开启通用线程池的能力,则对每个计算任务都使用一个新的线程去运行。
为了让 Stream 流代码看起来即简洁又炫酷,java8 又加入了两个新特性:Lambda 表达式和接口的默认方法。
前者可以缩短代码行数,更接近人类阅读习惯;后者让接口在演变时更顺畅,编译更少。
至于 Optional 以及新的日期和时间 API,使用它们会让你身心愉悦,甚至在阅读源代码之后,你的编程思想将得到升华。
Synchronized 为什么在多内核 CPU 上的执行成本很高?
多核 CPU 的每个处理器内核都有独立的高速缓存,加锁需要这些高速缓存同步运行,然而这又需要在内核间进行较慢的缓存一致性协议通信。
函数式编程的基础接口
Consumer- 消费者Function- 函数Predicate- 谓词Supplier- 提供者
Consumer
官方 API 描述:
Represents an operation that accepts a single input argument and returns no result. Unlike most other functional interfaces, Consumer is expected to operate via side-effects.
翻译:
表示接受单个输入参数且没有返回值的操作,与其他大多数函数式接口不同的是,消费者预期借助于副作用(译注:即修改输入参数)进行操作。
核心代码:
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> {
accept(t);
after.accept(t);
};
}
}
说明:
函数式接口通常只包含一个待实现的接口方法,在这里是 accept 方法,它表示【接受】一个任意类型(泛型)的对象,无返回值。
默认方法 andThen,表示先接受当前消费者,然后(and then)接受传入的 after 消费者。**
它可以看作是简单的责任链设计模式。**
示例:
public class ConsumerDemo {
public static void main(String[] args) {
Optional.ofNullable(args)
.filter(ConsumerDemo::isArrayNotEmpty)
.map(ConsumerDemo::randomValueOfRange)
.ifPresent(printConsumer().andThen(System.err::println));
}
private static boolean isArrayNotEmpty(String[] arrays) {
return arrays != null && arrays.length > 0;
}
private static String randomValueOfRange(String[] arrays) {
if (arrays == null || arrays.length == 0) {
return "(empty)";
}
return arrays[(int) (Math.random() * arrays.length)];
}
private static Consumer<String> printConsumer() {
return System.out::println;
}
}
Function
官方 API 描述:
Represents a function that accepts one argument and produces a result.
翻译:
表示接受一个参数并产生结果的函数。
核心代码:
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
说明:
apply 方法表示【应用】一个泛型对象,返回另一个泛型对象。可以简单的记忆为,第一个泛型对象 T 进,第二个泛型对象 R 出。
静态方法 identity 表示【一致性】,它将应用的泛型对象直接返回,不进行任何处理。
identity 方法的典型应用场景是将 Stream 转为 Map 时,对 key 或 value 的转换需要传入一个 Function
接口,此时可以直接使用 identity 方法避免额外的 Lambda 表达式编码。
示例:
public class IdentityDemo {
public static void main(String[] args) {
Map<String, String> maps = Stream.of("1", "3", "5", "7", "9")
.collect(Collectors.toMap(Function.identity(), Function.identity()));
System.out.println(maps);
}
}
默认方法 compose 表示【组合】前置 Function 函数,它首先调用前置函数的应用方法,将泛型对象 V 转为泛型对象 T
,随后调用当前函数的应用方法,将泛型对象 T 转为泛型对象 R。
compose
方法的典型应用场景是存在一个特定函数,在输入参数不兼容的情况下,通过使用组合方法进行参数转换,让特定函数变成适应任何类型的通用函数。
示例:
public class ComposeDemo {
public static void main(String[] args) {
List<Double> doubles = Stream.of("1", "3", "5", "7", "9")
.map(halving().compose(Integer::parseInt))
.collect(Collectors.toList());
System.out.println(doubles);
}
private static Function<Integer, Double> halving() {
return it -> it / 2.0;
}
}
默认方法 andThen 与 compose 的行为相反,它先处理当前函数的输入参数,随后通过 after 函数返回预期类型的对象。
Predicate
官方 API 描述:
Represents a predicate (boolean-valued function) of one argument.
翻译:
表示一个参数的谓词(布尔值函数)。
核心代码:
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
default Predicate<T> negate() {
return (t) -> !test(t);
}
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
说明:
test 方法表示【评估】一个泛型对象,返回布尔值用于后续判断。
静态方法 isEqual 表示操作对象【是否等于】目标引用对象,通常情况下使用 Object.equals
方法进行比较,也支持目标引用对象为 null 时的比较。
默认方法 and 表示【与】操作,通过短路逻辑与联系两个谓词,如果当前谓词返回 false,则不再评估传入的 other 谓词。
默认方法 negate 表示【取反】操作,是将当前谓词的返回值进行取反,获得一个新的谓词。
默认方法 or 表示【或】操作,通过短路逻辑或联系两个谓词,如果当前谓词返回 true,则不再评估传入的 other 谓词。
Supplier
官方 API 描述:
Represents a supplier of results. There is no requirement that a new or distinct result be returned each time the supplier is invoked.
翻译:
表示一个结果的提供者。 不要求每次调用提供者都返回一个新的或不同的结果。
核心代码:
@FunctionalInterface
public interface Supplier<T> {
T get();
}
说明:
get 方法表示【获得】一个泛型对象。
提供者没有静态方法和默认方法。
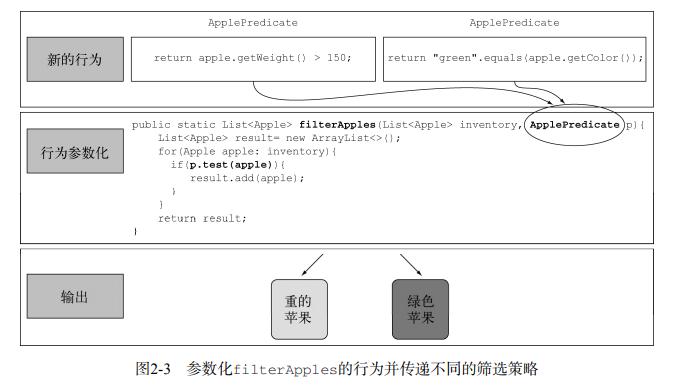
行为参数化
引用《Java 8 实战》2016 年 4 月第 1 版中,第二章开头的一段话:
行为参数化就是可以帮助你处理频繁变更的需求的一种软件开发模式。
在软件开发领域,频繁变更的需求是坏味道代码的罪魁祸首之一。为此,大神们总结出【策略设计模式】,再遇到新需求,就可以通过建立新的策略类来应对。
但不幸的是,随着需求的不断变更,越来越多的策略类占据了源代码空间,对于新人来说,非常不友好,且策略类大多数是重复的模板代码,完全没必要。
通过观察,大神们发现策略类中唯一有意义的是方法实现的代码块,如果将它作为参数传递给调用方,则可以完全抹除模板代码,使得源代码更方便阅读,且不损失任何的功能。
于是借助 java8 的 Lambda 表达式,大神们成功实现了行为参数化,即将包含业务逻辑的代码块作为参数传递给调用方。
概念如图所示:
Stream 流 API
流,即先从源开始获取元素序列,接着描述一系列数据处理操作,最后通过内部迭代得到最终的结果。
- 元素序列——类似集合,但不同的地方在于,集合讲究数据,流讲究计算
- 源——可以来自集合、数组或输入/输出资源,需要注意的是,从有序集合生成的流,本身也会保留原有的顺序
- 数据处理操作——可以参考数据库操作,以及函数式编程的常用操作,一般来说,这些操作可以顺序执行,也可以并行执行
- 内部迭代——流的迭代操作是在内部进行的,这有利于流的开发者进行不断优化,对于我们而言,只需要关注功能即可
流的特性:
- 流只能遍历一次
- 流使用内部迭代
- 流通过中间操作描述如何处理数据,但不对流元素产生作用
- 流通过终端操作对流元素产生作用,并返回相应的结果
相关操作:
| 操作 | 类型 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
|---|---|---|---|---|
| filter | 中间 | Stream<T> |
Predicate<T> |
T -> boolean |
| distinct | 中间(有状态-无界) | Stream<T> |
||
| skip | 中间(有状态-有界) | Stream<T> |
long |
|
| limit | 中间(有状态-有界) | Stream<T> |
long |
|
| limit | 中间 | Stream<T> |
Predicate<T> |
T -> boolean |
| map | 中间 | Stream<T> |
Function<T, R> |
T -> R |
| flatMap | 中间 | Stream<T> |
Function<T, Stream<R>> |
T -> Stream<R> |
| sorted | 中间(有状态-无界) | Stream<T> |
Comparator<T> |
(T, T) -> int |
| anyMatch | 终端 | boolean |
Predicate<T> |
T -> boolean |
| noneMatch | 终端 | boolean |
Predicate<T> |
T -> boolean |
| allMatch | 终端 | boolean |
Predicate<T> |
T -> boolean |
| findAny | 终端 | Optional<T> |
||
| findFirst | 终端 | Optional<T> |
||
| forEach | 终端 | void |
Comparator<T> |
T -> void |
| collect | 终端 | R |
Collector<T, A, R> |
|
| reduce | 终端(有状态-有界) | Optional<T> |
BinaryOperator<T> |
(T, T) -> T |
| count | 终端 | long |
何时使用 findFirst 和 findAny:
你可能会想,为什么会同时有
findFirst和findAny呢? 答案是并行。找到第一个元素在并行上限制更多。 如果你不关心返回的元素是哪个,请使用findAny,因为它在使用并行流时限制较少。
无状态:
诸如
map或filter等操作会从输入流中获取每一个元素,并在输出流中得到0或1个结果。 这些操作一般都是无状态的:它们没有内部状态(假设用户提供的 Lambda 或方法引用没有内部可变状态)。
有界、无界、有状态:
诸如
reduce、sum、max等操作需要内部状态来累积结果。 在上面的情况下,内部状态很小。 在我们的例子里就是一个int或double。 不管流中有多少元素要处理,内部状态都是有界的。 相反,诸如sort或distinct等操作一开始都和filter和map差不多——都是接受一个流,再生成一个流(中间操作),但有一个关键的区别。 从流中排序和删除重复项时都需要知道先前的历史。 例如,排序要求所有元素都放入缓冲区后才能给输出流加入一个项目,这一操作的存储要求是无界的。 要是流比较大或是无限的,就可能会有问题(把质数流倒序会做什么呢?它应当返回最大的质数,但数学告诉我们它不存在)。 我们把这些操作叫作有状态操作。
收集与归约:
你可能想知道,
Stream接口的collect和reduce方法有何不同,因为两种方法通常会获得相同的结果。 以错误的语义使用reduce方法还会造成一个实际问题:这个归约过程不能并行工作,因为由多个线程并发修改同一个数据结构可能会破坏List本身。 在这种情况下,如果你想要线程安全,就需要每次分配一个新的List,而对象分配又会影响性能。 这就是collect方法特别适合表达可变容器上的归约的原因,更关键的是它适合并行操作。
Collectors 类的静态工厂方法:
| 工厂方法 | 返回类型 | 用途 |
|---|---|---|
toList |
List<T> |
把流中所有项目收集到一个 List |
使用示例:List<Dish> dishes = menuStream.collect(toList()); |
||
toSet |
Set<T> |
把流中所有项目收集到一个 Set,删除重复项目 |
使用示例:Set<Dish> dishes = menuStream.collect(toSet)); |
||
toCollection |
Collection<T> |
把流中所有项目收集到给定的供应源创建的集 |
使用示例:Collection<Dish> dishes = menuStream.collect(toCollection(), ArrayList::new); |
||
counting |
Long |
计算流中元素的个数 |
使用示例:long howManyDishes = menuStream.collect(counting()); |
||
summingInt |
Integer |
对流中项目的一个整数属性求和 |
使用示例:int totalCalories = menuStream.collect(summingInt(Dish::getCalories)); |
||
averagingInt |
Double |
计算流中项目 Integer 属性的平均值 |
使用示例:double avgCalories = menuStream.collect(averagingInt(Dish::getCalories)); |
||
summarizingInt |
IntSummaryStatistics |
收集关于流中项目 Integer 属性的统计值,例如最大、最小、总和与平均值 |
使用示例:IntSummaryStatistics menuStatistics = menuStream.collect(summarizingInt(Dish::getCalories)); |
||
joining |
String |
连接对流中每个项目调用 toString 方法所生成的字符串 |
使用示例:String shortMenu = menuStream.map(Dish::getName).collect(joining(", ")); |
||
maxBy |
Optional<T> |
一个包裹了流中按照给定比较器选出的最大元素的 Optional,或如果流为空则为 Optional.empty() |
使用示例:Optional<Dish> fattest = menuStream.collect(maxBy(comparingInt(Dish::getCalories))); |
||
minBy |
Optional<T> |
一个包裹了流中按照给定比较器选出的最小元素的 Optional,或如果流为空则为 Optional.empty() |
使用示例:Optional<Dish> lightest = menuStream.collect(minBy(comparingInt(Dish::getCalories))); |
||
reducing |
归约操作产生的类型 | 从一个作为累加器的初始值开始,利用 BinaryOperator 与流中的元素逐个结合,从而将流归约为单个值 |
使用示例:int totalCalories = menuStream.collect(reducing(0, Dish::getCalories, Integer::sum)); |
||
collectingAndThen |
转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数 |
使用示例:int howManyDishes = menuStream.collect(collectingAndThen(toList(), List::size)); |
||
groupingBy |
Map<K, List<T>> |
根据项目的一个属性的值对流中的项目作问组,并将属性值作为结果 Map 的键 |
使用示例:Map<Dish.Type, List<Dish>> dishesByType = menuStream.collect(groupingBy(Dish::getType)); |
||
partitioningBy |
Map<Boolean, List<T>> |
根据对流中每个项目应用谓词的结果来对项目进行分区 |
使用示例:Map<Boolean, List<Dish>> vegetarianDishes = menuStream.collect(partitioningBy(Dish::isVegetarian)); |
Stream API 的数值计算
如果流中的元素为数值,比如 int、long 等基本数据类型,则应该使用 IntStream 流而非 Stream<Integer>
流,原因在于,Stream<Integer> 流在计算时,需要将 Integer 自动拆箱为 int 数值,等计算完毕后,又要自动装箱为 Integer
类。在流中的元素数量较多时,将导致性能急剧下降,且无法得知 null 值是代表空,还是 0 值,还是 NaN 值。
总之在遇到数值计算时,一定要转为对应类型的流,不仅可以增加性能,还可以获得更强大的计算函数,比如 Max、Sum 等等。